"不装 TeX,网页里怎么就把
.tex渲染出来了?" 答案是两套完全不同的技术,对应两类需求。混淆它们,是大多数人理解偏差的根源。
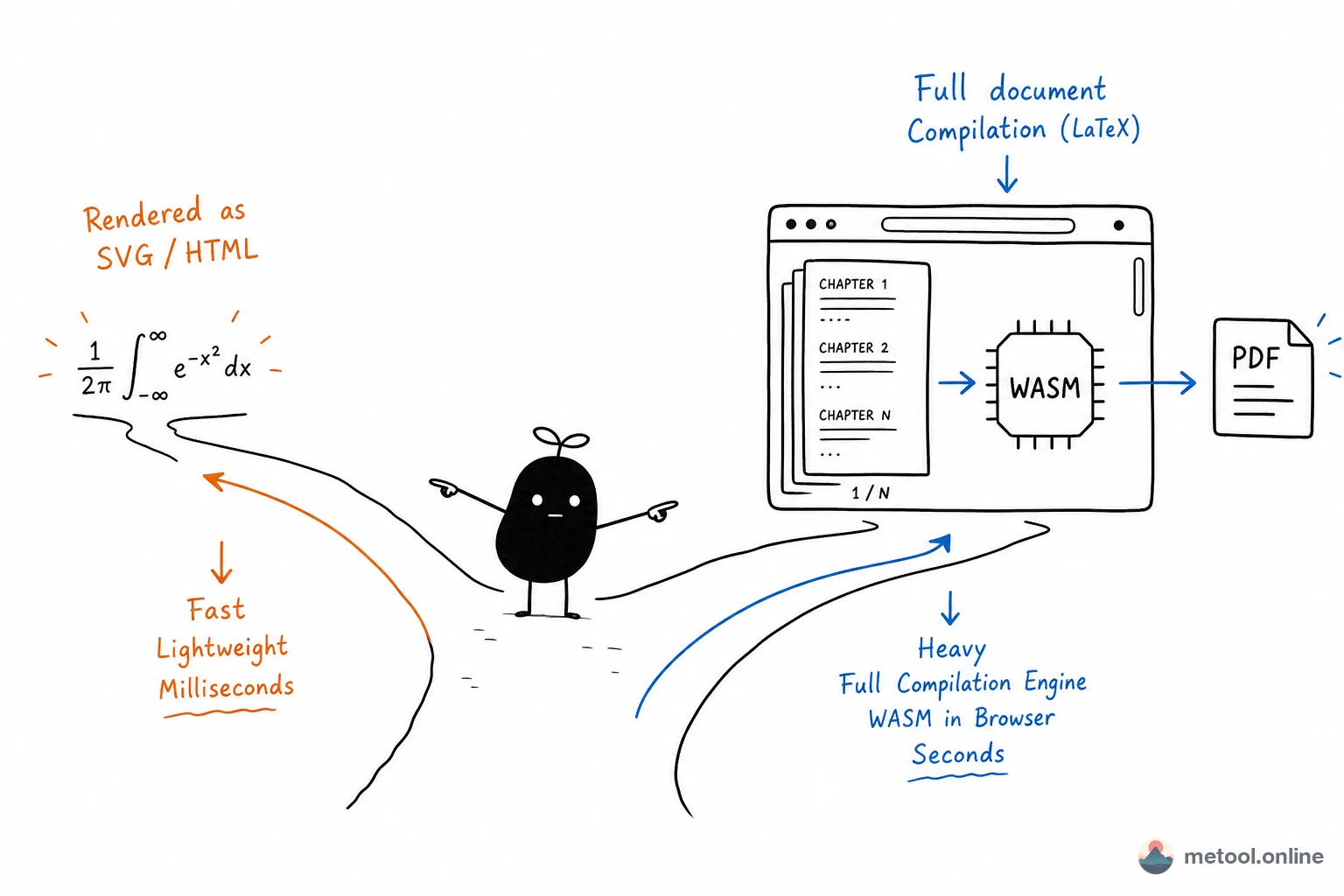
先分清两类需求
"在浏览器里处理 LaTeX"其实是两件事,技术栈不同:
- 只渲染数学公式:网页内联公式、公式编辑器;
- 编译整篇
.tex文档:含\documentclass、章节、表格、分页、参考文献,输出 PDF。
第一类是轻量的"语法转换",第二类是完整的"排版编译"。下面分别看。
一、公式渲染:KaTeX / MathJax
把 \frac{a}{b}、积分、矩阵渲染成漂亮公式,靠的是 KaTeX 或 MathJax 这类 JavaScript 库。它们做的是把 LaTeX 公式语法解析并转换成 HTML/SVG/MathML,并不运行真正的 TeX 引擎。两者取舍很实际:
| 维度 | KaTeX | MathJax |
|---|---|---|
| 渲染方式 | 同步,DOM 一次写入 | 异步,可能多次排版 |
| 体积与速度 | 更轻、更快 | 更重、更慢 |
| TeX 命令覆盖 | 常用数学命令子集 | 覆盖更广,扩展更多 |
| 典型场景 | 公式密集、实时预览 | 需要冷门命令或复杂环境 |
这类方案本质是字符串到标记的转换,通常在毫秒级完成,不涉及分页、交叉引用或参考文献引擎。
二、整篇文档编译:WebAssembly 版 TeX
要把一份完整 .tex 编译成分页 PDF,公式库远远不够,需要真正的 TeX 引擎。关键技术是 WebAssembly(WASM):TeX 引擎原本是 C 语言写的本地程序,编译成 WASM 字节码后,可在浏览器 JS 引擎里以接近原生的速度运行。代表实现有 SwiftLaTeX、texlive.js 等,它们把 TeX 排版内核、必要字体和常用宏包一并打进前端资源包。
典型数据流:.tex 源码 → 浏览器内 WASM TeX 运行时 → 本地完成排版与分页 → 输出 PDF。编译算力来自用户设备,不经过远端 TeX 服务。
客户端 WASM 与服务端 TeX:架构取舍
同一需求(网页里得到 PDF)可以走两条架构路,工程权衡如下:
| 维度 | 浏览器 WASM TeX | 远端/自建 TeX 服务 |
|---|---|---|
| 首次访问 | 需下载 WASM + 字体(MB 级,可缓存) | 客户端几乎无 TeX 相关下载 |
| 宏包与字体 | 打包常用子集,体积受限 | 可挂载完整 TeX Live |
| 算力与扩展 | 受单用户设备 CPU/内存约束 | 服务器横向扩展,但需配额与隔离 |
| 源码路径 | 默认留在用户浏览器内存/本地 FS 抽象层 | 需上传 .tex 与依赖文件到服务端 |
| 离线 | 资源缓存后可离线编译 | 依赖网络与服务可用性 |
| 运维 | 静态资源 + CDN,无编译队列 | 需防滥用、沙箱、超时与磁盘清理 |
没有绝对更优:轻量文档、宏包需求可预测时,WASM 把编译成本摊到客户端;冷门宏包、大部头工程或需与完整 BibTeX 工具链深度集成时,传统 TeX 发行版仍更可靠。
能力边界与已知限制
浏览器端完整编译不是 TeX Live 的 1:1 替代,常见边界包括:
- 宏包覆盖有限:前端 bundle 只能带常用子集,
\usepackage指向未打包宏包时会直接失败; - 首次加载体积:WASM 引擎与字体需一次性下载,弱网或冷启动时延迟明显;
- 超大工程:几百页、多文件
\input、复杂参考文献需多趟编译时,浏览器内存与长任务调度不如本地 TeX 稳定; - 运行时约束:单线程主线程阻塞、Tab 内存上限、无完整 shell 工具链,极端文档可能卡顿或 OOM;
- 公式库边界:KaTeX/MathJax 不处理
\documentclass、浮动体、目录生成等文档级语义,误用在整篇.tex上只会得到公式片段而非 PDF。
判断 workload 是否适合浏览器 WASM,关键看宏包是否在打包列表内、文档规模与编译趟数是否在浏览器可承受范围内。
小结
浏览器里处理 LaTeX 依赖两套技术:公式渲染(KaTeX/MathJax,语法→标记)与整篇编译(WASM TeX,完整排版引擎)。前者轻、覆盖窄;后者重、接近真实 TeX 但受打包与运行时限制。厘清「语法转换 vs 排版编译」的分野,再对照客户端与服务端架构表,就能按文档复杂度与宏包需求选对实现路径。